| |
topicmap.a7111.com
Einführung in semantikbasierende Anwendungen
topicmap.a7111.com: topic maps web ontology language
taxonomie ontologie semanitsche anwendungen
Menü
Kontakt:
|
Semantische Konzepte
Die Sprache verbirgt Überraschungen, diesen Topos hört man gewöhnlich unter Literatinnen und in Kreisen schöngeistiger Gelehrter. Workshops zur Semiologie digitaler Systeme sind nicht der Ort, an dem man sie erwartet. In diesem Kontext sind solche Überraschungen eher verpönt. Sie sind der Grund für Fehlfunktionen eines Programms. Wissensmanagement ist als Wort schon ein Paradoxon. Wissen, als zur Anwendung gebrachte Information, existiert nur in den Köpfen von Menschen. Wissen ist nicht fassbar, nicht zählbar und ohne den Kontext des Wissensträgers ist es oft wertlos. In Hinsicht auf ein Management von Wissen spricht man demnach zum einen von gezieltem Management von Informationen erweitert um den Human Ressources Aspekt.
:: Bedeutung der Begriffe, Begriffe der Bedeutung
Die inhaltliche Bedeutung, die einem Wort zugeordnet wird und so einen Begriff bildet ist relativ zum sprachlichen Kontext. Ein Poet in Ausübung seiner Berufung verbindet mit dem Wort Licht eine andere inhaltliche Bedeutung als ein Physiker als Physiker. Auf alltagsprachlicher Basis besteht die unausgesprochene Vereinbarung, Worte in ihrer allgemeinsten Bedeutung zu verwenden, sozusagen auf einen kleinsten gemeinsamen Nenner zu reduzieren. Steckt man den oben erwähnten Physiker und den Poeten gemeinsam in einen dunklen Raum, so werden sie wahrscheinlich auf alltagsprachlicher Basis darin übereinstimmen, dass etwas mehr Licht nicht schaden könnte - Licht in seiner allgemeinsten Bedeutung, als Gegensatz zu Dunkelheit.
Für Informationstechnologie ist dieses Phänomen insofern relevant, wenn es darum geht digitale Systeme so zu konzipieren, dass sie automatisch Begriffe miteinander verknüpfen, ähnlich der menschlichen Weise des Schlussfolgerns, und eine einheitliche Terminologie dafür Grundvoraussetzung ist. Begriffe aus dem Erfahrungsbereich sind generell kaum objektivierbar, sondern an ein denkendes Subjekt gebunden, an sein Verständnis eines Begriffes, also welche inhaltliche Bedeutung es einem Wort zuordnet.

Ein Beispiel zur Erläuterung: Der mathematische Kreis ist kein erfahrungsweltlicher Gegenstand seine Definition ist exakt festlegbar, erschöpft sich in der Beschreibung seiner Form und ist objektiv. Bei dem archäologischen Begriff Steinkreis, also eine Sache aus unserer Erfahrungswelt, liegt der Fall schon wesentlich komplizierter. Wie gelangt man zu einer Definition von Steinkreis, und zwar im archäologischen Sinne, die das allgemeinste Wesentliche erfasst, und dennoch exakt genug ist, dass ein digitales System damit arbeiten kann. Die bloße Angabe von Material (Stein) und Form (rund), die bis zu einem gewissen Grade naturwissenschaftlich erfassbar und somit objektivierbar sind, reicht nicht aus. Wenn man draußen im Garten zehn Steinchen halbwegs kreisförmig anordne, so ist das noch nicht Stonehenge. Was einen Steinkreis wie Stonehenge zu einem archäologischen Interessensgegenstand macht, ist sein Errichtungszweck. Um diesen zu definieren, muß man wiederum eine Menge Begriffe verwenden, die noch problematischer festzulegen sind als Steinkreis. Religion und Kult zum Beispiel.
::: Metadaten und Metasprachen
:::: Metadaten, Semantische Anreicherung von Dokumenten
Metadaten sind dem Wortsinn nach Daten über Daten. Das bekannteste Vokabular für Metadaten ist Dublin Core mit einem definierten Satz an Attributen für eine einheitliche Kategorisierung von Webseiten. Diese Attribute sind allerdings vorwiegend von administrativen Nutzen und bieten kaum Hilfe für eine inhaltliche Charakterisierung von Dokumenten.
Das folgende HTML-Codebeispiel zeigt die formale Beschreibung einer Buch-Publikation eines Verlages mit Dublin-Core Metadaten:

:::: Meta-Sprachen, Semantische Dokumente
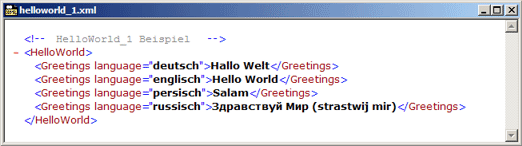
Meta-Sprachen wie die Extensible Markup Language XML gehen eine Schritt weiter und erlauben, Dokumente vollständig nach semantischen Gesichtspunkten zu modellieren. Im einfachsten Fall erfindet man das passende Markup-Vokabular, wie das kleine Hello-World Beispiel zeigt:
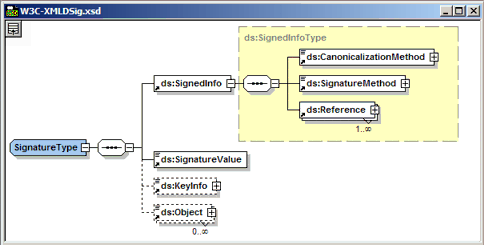
In der Praxis finden sich natürlich wesentlich komplexere Dokumentmodelle, wie ein Ausschnitt aus dem für Digitale Signaturen relevanten XMLDSig-Schema zeigt (nachfolgende Abbildung). Hier ist bereits erkennbar, dass die gewählte Semantik nur mehr bedingt für den menschlichen Leser gedacht ist und die maschinelle Verarbeitbarkeit im Vordergrund steht.
:: Weiterführende Konzepte
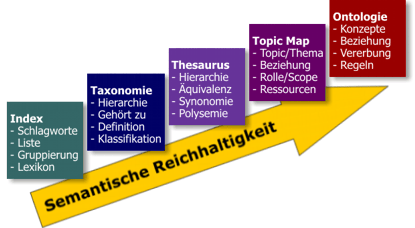
Neben der grundsätzlichen Möglichkeit, Dokumente gezielt durch Metadaten anzureichern und damit für Maschinen verständlicher zu machen, sind für zukünftige Anwendungen Beschreibungskonzepte interessant, die unabhängig von den beschriebenen Dokumentressourcen existieren. Die entsprechenden Konzepte sind in der folgenden Grafik dargestellt und nachfolgend im Detail beschrieben.
::: Index, Kontrolliertes Vokabular
In praktisch jedem Wissensbereich kommen unterschiedliche Begriffe vor, die ein und dasselbe Ding bezeichnen. Dabei kann es sich um Synonyme handeln, um entartetes Kauderwelsch, oder um fremdsprachliche Ausdrücke, die parallel zur deutschen Übersetzung verwendet werden. Ein kontrolliertes Vokabular ist die pragmatische Einigung auf ein gemeinsam verwendetes Vokabular bzw. auf eine einheitliche Schreibweise von Begriffen, z.B Benutzer statt User oder Client.
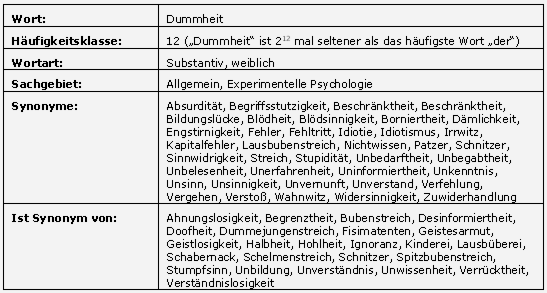
Für den Begriff Dummheit finden sich zum Beispiel weit über 100 Synonyme (die nachfolgend als Abbildung und nicht als Text dargestellt werden, um diese Webseite nicht bei Suchmaschinen in Verruf zu bringen):
::: Taxonomie
Taxonomien gehen einen Schritt weiter. Hier werden die Begriffe nach logischer Zusammengehörigkeit hierarchisch geordnet, ähnlich den Gelben Seiten in einem Telefonbuch. Taxonomien findet man praktisch überall, zum Beispiel für die Kategorisierung von Lebewesen in der Biologie, in Produktkatalogen, oder wie die nachfolgende Abbildung zeigt, für die lexikalische Beschreibung von Städten.
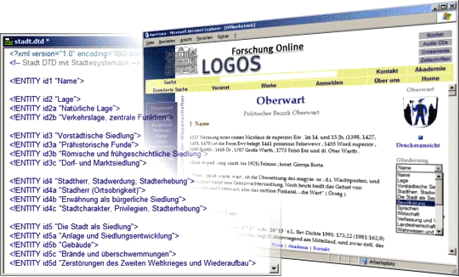
Das abgebildete Österreichische Städtebuch verwendet eine aus über 80 definierten Begriffen bestehende Systematik, die als Entitäten in eine Document Type Definition (DTD) eingebettet sind. Aus dieser Systematik wird sowohl die sichtbare Kapitelstruktur wie auch die funktionelle Navigation innerhalb der Webseite erzeugt. Das eigentlich Interessante an diesem Konzept ist, dass die semantische Anreicherung der Stadtbeschreibungen nicht durch eingebettete Metadaten im XML-Dokument, sondern durch externe, in Kategorien geordnete Begriffs-Entitäten erfolgt.
::: Thesaurus
Thesauri sind eine formale Erweiterung von Taxonomie-Strukturen. Neben der hierarchischen Aufteilung in Kategorien weisen Thesauri zusätzliche Elemente zur Beschreibung von begrifflichen Zusammenhängen auf, unter anderem:
- BT: Broader term, bezeichnet den übergeordneten Begriff, also die Kategorie;
- NT: Narrower term, verweist auf untergeordnete Begriffe;
- SN: Definiert den Gültigkeitsbereich (Scope) des Begriffes;
- USE: Verweist auf synonyme Begriffe, die vorzugsweise zu verwenden sind;
- UF: Verweist auf synonyme Begriffe, die nicht verwendet werden sollen;
- RT: Related term, verweist auf verwandte Begriffe, die weder übergeordnet
noch untergeordnet sind.
::: Ontologie
Der Begriff Ontologie stammt aus der Philosophie und beschreibt den Zweig der Metaphysik, der sich mit dem Wesen des Seins befasst. In der Informatik wird unter einer Ontologie die konzeptuelle Formalisierung eines Wissensbereiches verstanden, also ein weit über Taxonomien und Thesauri hinausgehender Ansatz, Wissen für Menschen und Rechner eindeutig zu beschreiben:
An ontology is a formal, explicit specification of a
shared conceptualization for a domain of interest
Ontologien basieren auf dem Strukturkonzept von Taxonomien und erweitern dieses mit weiterführenden Beziehungsstrukturen, Regeln und Axiome. Wenn nur einfache Beziehungen in der Art von broader/narrower term dargestellt werden, spricht man von leichtgewichtigen Ontologien und verwendet sie im Sinne von Taxonomien. Schwergewichtige Ontologien bieten wesentlich mehr Möglichkeiten und erfordern auch erheblich mehr Aufwand bei der Modellierung. Die W3C-Recommendation OWL unterscheidet zum Beispiel zwischen drei Ontologiemodellen:
- OWL-Lite: leichtgewichtige Ontologie, einfache Regeln (constraints) sind formulierbar;
- OWL-DL: schwergewichtige Ontologie, vielfältige Modellierungsmöglichkeiten,
die Verwendbarkeit des Modelles wird garantiert (all computations will finish in finite time);
- OWL Full: schwergewichtige Ontologie mit zusätzlichen Modellierungsmöglichkeiten,
allerdings ohne die bei OWL-DL erwähnte Garantie der Verwendbarkeit.
Ontologien bestehen im Wesentlichen aus:
- Begriffen: Begriffe werden auch als Klassen bezeichnet, sie beschreiben gemeinsame
Eigenschaften und können in einer Klassenstruktur mit Über- und Unterklasse angeordnet
sein (z.B. Stadt - Land);
- Instanzen: Instanzen repräsentieren konkrete Objekte, die von allgemeinen Klassen
abgeleitet werden (z.B. Stadt - Wien);
- Relationen: Relationen beschreiben Beziehungen, die zwischen Klassen bestehen,
z.B. Stadt liegt in Land, oder Land enthält Stadt. Genau so wie Begriffe können auch
Beziehungen Eigenschaften haben, z.B. transitive oder symmetrische Beziehung;
- Axiome: Axiome sind Aussagen, die immer wahr sind. Diese werden dazu verwendet,
Wissen zu repräsentieren, das nicht aus anderen Begriffen abgeleitet werden kann.
Bei der Ontologie-Modellierung geht man üblicherweise von einer offenen Welt-Annahme aus, was unter anderem bedeutet, dass Ontologien von anderen Ontologien verwendet oder sogar erweitert werden können. Dieser Mechanismus ist besonders wichtig, da damit die weite Verbreitung und der gegenseitige Nutzen gefördert wird. Es ist aber auch abzusehen, dass bei der Zusammenführung unabhängig entstandener Ontologien widersprüchliche Szenarien entstehen können. Dies betrifft insbesonders den anwendungsspezifischen Teil einer Ontologie, der zwischen allgemeinen Überbegriffen (Upper Domain Ontology) und formalisierten Grundbegriffen (Lower Domain Ontology) im sogenannten Chestnut-Modell eingebettet ist (nach Staab [24]).
Konsistente Ontologien sind vermutlich nur durch gemeinsames Design (collaborative approach) und durch konsequente Verwendung von publizierten Upper- und Midlevel-Ontologien beziehungsweise von Published Subjects machbar (siehe Folgekapitel).
Das nachfolgende Kapitel beschäftigt sich mit den zugehörigen Standards & Initiativen.
Standards und Initiativen
Das nachfolgend abgebildete W3C-Ebenenkonzept zeigt Standards und Initiativen, die für das Semantische Web und für Service orientierte Architektur (SOA) von besonderer Bedeutung sind. Dunkel gefärbten Ebenen repräsentieren dabei etablierte Standards wie zum Beispiel Unicode, URI und XML.
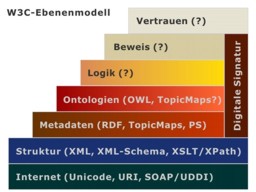
In den mittleren Ebenen findet zur Zeit ein laufender Entwicklungsprozess statt, der vom W3C (RDF/OWL) und ISO (Topic Map) betrieben wird. Neben den Basismodellen OWL und Topic Map sind es vor allem die zugehörigen Komponenten wie zum Beispiel Published Subjects (PSI) und Upper-Ontologies, die vordringlich als Standards publiziert sein müssen, um alle Beteiligten zu einem gemeinsamen Vorgehen zu motivieren. Für die obersten Schichten Logik, Beweis und Vertrauen existieren zur Zeit kaum Ansätze und Anforderungsspezifikationen.
Die digitale Signatur wird in einigen Ebenen eine große Rolle spielen, konkret: Nachweis der Authentizität, Qualität der Information und Reputation des Autors. Auch Ansätze zur Vertrauensbildung sind vorstellbar, zum Beispiel durch die Einbindung unabhängiger Trust Center und Publisher.
:: Standards
::: URI (Uniform Resource Identifier)
Die allgemeine Spezifikation URI und die im Web verwendete konkrete Implementierung URL (Uniform Resource Locator) beschreiben eindeutige Namens- und Adressierungsschemas. Eine URL der Form http://www.help.gv/ enthält zum Beispiel die Angabe des Transportprotokolls http oder ftp und die von rechts nach links hierarchisch strukturierte Zieladresse beginnend mit Domänenbezeichnungen wie gov, org, com und beliebige, durch Punkt getrennte Namenskonstrukte, zum Beispiel www.help.
Dokumentpfade und Dokumentnamen werden in der allgemein üblichen Pfadnotation an die Basis-URL angehängt, zum Beispiel /produkte/produkt1.xml. Zusätzliche Fragment-Identifier erlauben, innerhalb der genannten Dokumente punktgenau zu navigieren, zum Beispiel /produkt1.xml#preis. Dieses Adressierungsart wird im Zusammenhang mit ontologiebasierenden Systemen auch für die Identifizierung von Begriffen (Published Subjects) verwendet.
::: Simple Object Access Protocol SOAP
SOAP ist ein XML-basierendes Protokoll, das auf dem im Internet üblichen HTTP-Protokoll aufsetzt und die aktive Kommunikation zwischen Services auch über Firewalls hinweg ermöglicht. SOAP ist in erster Linie für Service orientierte Architektur interessant (SOA), zukünftige semantische Anwendungen werden aber auf SOA-Services direkt oder indirekt aufbauen.
::: Unicode und ISO-10646 (UCS)
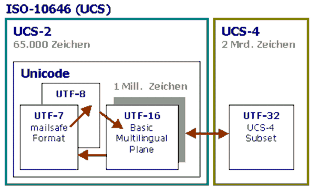
Unicode beziehungsweise ISO-10646 ist ein 16-Bit Zeichensatz, der die direkte Kodierung von über 65.000 Zeichen erlaubt. Historisch gesehen gibt es zwei Gründungsväter mit unterschiedlichen Zielsetzungen, nämlich das Unicode-Konsortium und die International Standardization Organisation (ISO).
Die ISO-Working Group ist im Rahmen der International Standardization Organisation (ISO) für die formale Standardisierung des Zeichensatzes zuständig, während sich Unicode als wirtschaftlich denkendes Konsortium um die Praxistauglichkeit bemüht (Eigenheiten wie Schriftrichtung usw).
Unicode erweitert den ISO-Standard mit den Transformationsformaten UTF-8 und UTF-16. Das UTF-8 Format ist eine Konzession an die englischsprachige Welt, es enthält den ASCII-Zeichensatz und erlaubt somit die kompakte 8-Bit Kodierung von englischen Texten. Das UTF-16 Format beinhaltet einen Erweiterungsmechanismus (Planes), der die zusätzliche Kodierung von etwa einer Million Zeichen ermöglicht.
Die europäischen Zeichensätze der ISO-8859-x Familie lassen sich üblicherweise problemlos in XML-Anwendungen alternativ zu Unicode verwenden beziehungsweise mit entsprechenden XML-Editoren nach Unicode transformieren.
::: Extensible Markup Language XML
XML ist eine Empfehlung des W3C-Konsortiums und somit ein defacto-Standard. Abgesehen von diesem formalen Status hat sich XML allein aufgrund seiner Eigenschaften als weltweit akzeptierter Standard für Archivierung, Transport und Präsentation von Dokumenten etabliert.
Technisch gesehen ist XML sowohl Sprachwerkzeug (Syntax), Metasprache (Modell) und Sprachfamilie (Anwendungen) zugleich.
Als Metasprache dient XML zur Entwicklung neuer Markup-Sprachen und als Sprachfamilie umfasst XML neben den Kernsprachen XSL, Xpath und XML-Schemas bereits mehrere hundert Anwendungssprachen wie zum Beispiel eBXML, GovXML, RuleML, LegalXML und XMLDSig.

Wichtige Eigenschaften von XML sind:
- Wellformedness, der Zwang zur korrekten Syntax-Notation,
- Validität, die Prüfmöglichkeit auf Konformität mit vorgegebenen Dokumentmodellen (DTDs oder Schemas),
- und die strikte Trennung zwischen Inhalt, Struktur und Präsentation.
:: Initiativen
::: Published Subjects
Published Subjects sind eine Empfehlung der Organization for the Advancement of Structured Information Standards OASIS.
Published Subjects sind im Prinzip kontrollierte Vokabulare, die entweder Begriffsobjekte aus der realen Welt repräsentieren oder Begriffe eindeutig identifizieren. Mit Published Subjects wird sowohl die Zusammenführung von Topic Maps untereinander gefördert wie auch eine mögliche Interoperabilität mit anderen Standards erleichtert (z.B. OWL). Das Konzept der Published Subjects wird durch die nachfolgende Grafik verdeutlicht:
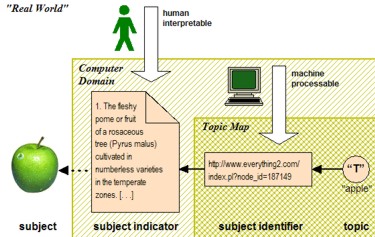
:::: Subject Indicator
Ein Apfel aus der realen Welt wird durch die Beschreibung auf einer Webseite als Begriffsobjekt repräsentiert, diese Webseite
ist definitionsgemäß ein Subject Indicator.
:::: Subject Identifier
Die Adresse (URL) der Webseite ist ein Subject Identifier. Diese Adresse kann im Sinne einer URI zugleich als eindeutige Objektidentität verstanden werden, ein Apfel der Güteklasse A kann somit in einer Lebensmittel-Ontologie eindeutig durch Angabe einer URI spezifiziert werden, ohne dass eine konkrete Webseite (URL) existiert.
:::: Subject Locator
Ein Subject Locator ist eine Adresse (URL), die direkt auf ein Begriffsobjekt verweist. Eine Webseite kann durchaus selbst Betrachtungsgegenstand sein, zum Beispiel, wenn ein Webdesigner auf die schön gestaltete Apfel-Webseite verweist. In diesem Fall ist die Webseite ein reales Objekt und keine Beschreibung.
::: Upper-Ontologies
Upper-Ontologies sind vergleichbar mit Published Subjects. Als konkrete Ontologien sind sie einsteils mächtiger als PS, lassen aber die feine Unterscheidbarkeit zwischen Begriffs-Repräsentation und Begriffs-Identifikation nicht zu. Ein entscheidendes Kriterium ist die Wahl der essentiellen Toplevel-Begriffe, die für alle folgenden Ontologien gemeinsam sind. Einer von viele möglichen Ansätzen ist die Wahl der Begriffe nach folgenden Kriterien (nach Gomez-Perez [8]):
- Essenz (rigidity): Eine Begriffseigenschaft ist essentiell, wenn sie für alle
abgeleiteten Begriffe erforderlich ist. Das Konzept Person ist essentiell,
da es für alle Personen-Instanzen gilt. Das Konzept Reisender ist anti-
essentiell, da alle Reisende auch potentielle Nichtreisende sind.
Das Konzept Rot ist nicht-essentiell, da es manchmal essentiell
(Blutstropfen) und manchmal nicht essentiell (Pulloverfarbe) ist.
- Voraussetzung (dependency): Wenn eine Begriffseigenschaft Voraussetzung
für andere Begriffe ist (ein Loch in der Wand setzt das Konzept Wand voraus).
::: RDF/RDFS, DAML+OIL
Der Ursprung dieser vom W3C unterstützen Sprachfamilie ist das framebasierende Ontologie-Konzept aus dem Forschungsgebiet der künstlichen Intelligenz (AI). Damit erklärt sich, dass einige der grundlegenden Konzepte, die sich in dieser Sprachfamilie finden, überaus anspruchsvoll sind und nicht unbedingt zu einer hohen Akzeptanz dieser Sprachen beigetragen haben.
Der framebasierende Ansatz definiert zwei Typen von Frames (Klassen und Instanzen) mit ihren hierarchischen Abhängigkeiten (Superclass-Of, Subclass-Of, Instance-Of) und Dekompositionen (disjoint, exhaustive, partition) sowie grundlegende Beziehungstypen (transitiv, reflexiv, symmetrisch und einige mehr). Vererbbare Eigenschaften der Klassen werden über so genannte Slots definiert, und Slot-Eigenschaften durch Facets im Detail spezifiziert.
:::: RDF/RDFS
Das Resource Description Framework RDF basiert auf drei Grundkomponenten:
- Resources: repräsentieren das zu beschreibende Thema (Subject)
- Properties: definieren Eigenschaften oder Beziehungen von Resourcen
- Statements: beinhalten Aussagen über Resourcen. Statements werden
als Triplets, bestehend aus Subjekt, Prädikat und Objekt formuliert und
entsprechen sinngemäß kurzen Sätzen wie Hans kauft ein Auto
Sowohl Resources wie auch Statements können als Objekte in einem Statement aufscheinen. Der zweite Fall ist dabei von grundlegender Bedeutung und wird Reifikation genannt. Eine Reifikation macht aus einer rein abstrakten Aussage oder Beziehung eine konkrete Resource. Der Satz Peter sagt, Hans kauft ein Auto enthält neben dem Subjekt Peter und dem Prädikat sagt auch ein Objekt, das aus einer Aussage reifiziert wurde.
RDFS erweitert das aus sieben Klassen und sieben Properties bestehende RDF-Modell um 16 weitere Elemente und gestattet damit weiterführende Modellierungen. Die konzeptionelle Stärke des RDFS-Modelles reicht aber für Ontologie-Anwendungen nicht aus.
:::: DAML+OIL
Die Darpa Agent Markup Language (DAML) entstand im Jahr 2000 als Forschungsprojekt der Defense Advanced Research Projects Agency (DARPA) des US-Verteidigungsministeriums und wurde als unclassified Project der Öffentlichkeit zugänglich gemacht. DAML war XML-konform, aber nicht für Ontologieanwendungen konzipiert. Etwa zur gleichen Zeit entstand die speziell für Ontologien entwickelte Sprache OIL (Ontology Inference Layer), die aber nicht XML-konform war.
Die Konzepte von DAML und OIL wurden zu DAML+OIL vereinigt und letztendlich mit geringfügigen Erweiterungen unter dem Namen OWL publiziert.
:::: Web Ontology Language OWL
Die Web Ontology Language OWL basiert auf RDFS und DAML+OIL und ist seit Februar 2004 offizielle Recommendation des W3C. OWL gibt es, wie bereits beschrieben, in drei verschiedenen Versionen: OWL-Lite, OWL DL und OWL Full. In Summe umfasst OWL DL 40 Elemente, davon 16 Klassen und 24 Properties. Am Beispiel einer publizierten Government-Ontologie lassen sich die vielschichtigen Modellierungsmöglichkeiten von OWL betrachten und diskutieren.
Der nachfolgende Ausschnitt aus der Government-Ontologie zeigt das Wurzelelement rdf:RDF mit den üblichen Namensraum-Deklarationen, im gegebenen Fall für das Vokabular rdf, rdfs und owl. Darüber hinaus werden mit zwei weiteren Deklarationen externe Ontologien eingebunden, eine allgemeine Upper-Ontologie (SUMO) und eine spezielle Geografie-Ontologie.

Weiters enthält das Beispiel eine Klassendefinition, IndependentState, modelliert als Unterklasse von
GeopoliticalArea und Nation, die beide in der Upper-Ontology SUMO definiert sind. Diese Klasse enthält auch eine Regel, die mit einer aus SUMO importierten Eigenschaft (disjoint-Property) formuliert wurde. Das disjoint-Property repräsentiert eine symmetrische Beziehung zwischen zwei beteiligten Klassen (bzw. Instanzen), im gegebenen Fall eine als Beziehung modellierte Ausschlussregel, nämlich dass unabhängige Staaten keine abhängigen Staaten sind und umgekehrt.
Diese für Menschen selbstverständliche Schlussfolgerung muss wie viele andere Details in einer Ontologie explizit unterstützt werden. Das disjoint-Property im Detail:

::: Topic Map
Der Topic Map Standard ISO 13250 definierte ein einfaches, aber sehr flexibles Datenmodell, das aus Topics, Associations und Occurrences besteht (auch als TAO bekannt). Der zugehörige XML-Syntax XTM 1.0 umfasst 19 Elemente. Im Gegensatz zu OWL verwendet Topic Map für die Modellierung von Eigenschaften nicht Properties, sondern Rollen und Bereiche (scopes).
Das vorangegangene Government-Beispiel würde mit Topic Map wie folgt modelliert werden:
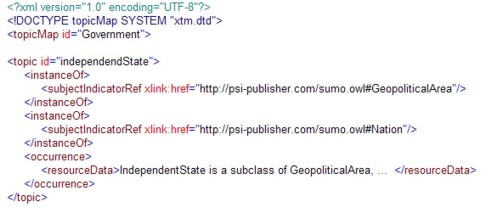
Die in OWL als Property formulierte disjoint-Beziehung entspricht im Topic Map Modell einer Association, also einer konkret modellierten Beziehung:

Ob Reasoning-Engines mit dieser Art der Modellierung zurecht kommen, sei dahingestellt. Die im Beispiel gezeigte Vermischung von OWL Ontologien mit Topic Map Ontologien durch die freizügige Verwendung von Subjektindikator-Referenzen in die OWL-Welt ist sowieso schon eine höchst fragwürdige Grenzüberschreitung. Damit wird aber besonders prägnant das Dilemma inkompatibler Ontologien aufgezeigt, egal, ob es sich dabei um die Überschreitung der Sprachgrenzen handelt, oder um inkonsistente Modelle innerhalb einer Sprachwelt.
Weiters ist aus den vorangegangenen Beispiel erkennbar, wie facettenreich und komplex sich das Innenleben einer Ontologie darstellt. Die Migration in die XML-Welt bedeutete für viele routinierte Experten aus der AI-Forschungswelt einen nicht unerheblichen Paradigmenwechsel, und für viele zukünftige Experten aus dem IT- oder betriebswirtschaftlichen Umfeld ist das in mehr als zwei Jahrzehnten gewachsene Wissen zu künstlicher Intelligenz nicht von heute auf morgen praktizierbar.
Topic Map bietet hier eine kleine Einstiegshilfe, da bewusst auf ein vorgegebenes Typenkonzept verzichtet wird. Somit ist dieser Standard relativ einfach erlernbar und universell für die Modellierung von Begriffsstrukturen, Regeln und Axiomen verwendbar. Ob dieser universelle Ansatz zielführend ist, ist schwer zu beurteilen - zumindest für Regeln ist die Erweiterung des Topic Maps Standards um eine eigene Constraint-Language (TMCL) geplant.
Das nachfolgende Kapitel beschäftigt sich im Detail mit den grundlegenden Konzepten und Modellierungsmöglichkeiten von Topic Maps.
XML Topic Maps
Topic Maps sind Wissenslandkarten, die über Wissensressourcen gelegt werden und damit eine schnelle und zielführende Orientierung in dieser Wissenslandschaft erlauben. Die nachfolgende Abbildung verdeutlicht dieses Prinzip:
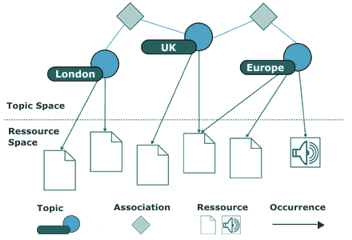
Im abstrakten Topic Space liegen die Begriffsdefinitionen (Topics), die auf reale Dokumente oder Wissensquellen verweisen (Occurrences), und die untereinander durch hierarchische oder logische Beziehungen verknüpft sind (Associations). Die Modellierung eines stabilen und schlussfolgerbaren Beziehungsgeflechtes zwischen den Begriffen im ontologischen Sinne ist die eine Herausforderung, die Fachleute, Linguisten und Philosophen gemeinsam lösen müssen. Ohne Zusammenarbeit (collaborative approach) würden vielleicht geniale, aber inkompatible Wissensinseln entstehen.
Genauso wie bei echten Landkarten ist der Maßstab von Topic Maps wählbar: Es können ganze Wissenskontinente wie z.B. Physik, Biologie oder Medizin im groben Maßstab dargestellt werden, und es können Territorien, Regionen, Bezirke bis hinab zu Stadtplänen mit immer mehr Details erfasst sein. Die Frage ist, wo liegt eine sinnvolle Untergrenze des Abbildungsmaßstabs? Macht es für Stadtpläne Sinn, die Zimmerausstattung der einzelnen Hotels zu erfassen, oder die Parkbänke in Grünzonen?
Ab einem bestimmten Detaillierungsgrad ist es sinnvoller, die beschriebenen Objekte direkt im Topic Space einzubetten, statt sie zu referenzieren. Aus Wissenslandkarten werden Wissensdokumente, die bereits alle Informationen enthalten, und die externe Ressourcen nur mehr im Sinne von Literaturverweisen verwenden. Diese Wissensdokumente sind von anderen Wissenslandkarten referenzierbar, mit dem Vorteil, dass ein einheitlicher Beschreibungsmechanismus bis in die letzte Instanz verwendet wird.
:: Inhaltsmodell (TAO)
Topic Maps basieren auf einem einfachen Konzept mit weniger als 20 funktionellen Elementen, die durch eine DTD beschrieben werden. Diese einfache Konzeption erkennt man bereits am beginnenden Inhaltsmodell: Eine Topic Map besteht aus Topics, Associations und einem Mechanismus für das Zusammenführen von Topic Maps, die in beliebiger Reihenfolge und Anzahl vorkommen dürfen:
<!-- topicMap: Topic Map document element -->
<!ELEMENT topicMap ( topic | association | mergeMap )* >
<!ATTLIST topicMap id ID #IMPLIED >
Topics und Associations bilden zusammen mit den in Topics verwendeten Occurrences das sogenannte TAO, also den Weltsinn des Topic Map Modells.
:: Topics
Das Inhaltsmodell von Topics erlaubt die Definition von Instanz-Beziehungen mit instance-Of, die Zuweisung einer eindeutigen Identität mit subjectIdentity, und Namen sowie Occurrences in beliebiger Reihenfolge. Darüber hinaus wird mit dem verpflichtenden id-Attribut eine eindeutige Identifizierbarkeit des Topics ermöglicht:

Anhand eines einfachen Beispiels für den Begriff Tomate werden die einzelnen Elemente schrittweise eingeführt und diskutiert.
::: BaseName und Scope
Ein Topic kann beliebig viele Namen besitzen, die sich z.B. regional unterscheiden. Um solche Feinheiten zu spezifizieren, kann ein optionaler Gültigkeitsbereich ( scope) für einen Namen angegeben werden, z.B. Österreich für Paradeiser:

::: Occurrence
Um Topics näher zu beschreiben, werden Occurrences verwendet, die auf zusätzliche Informationen verweisen, z.B. auf eine Abbildung.

::: SubjectIdentity
Um Topics eindeutig und unverwechselbar zu machen, ist die Bezugnahme auf allgemein akzeptierte (standardisierte) Begriffe sinnvoll, die von dafür zuständigen Organisationen als Published Subject Indicators publiziert werden.

Das Inhaltsmodell von subjectIdentity bietet noch zwei weitere Möglichkeiten zur Festlegung der Identität, nämlich den Bezug auf eine Ressource ( resourceRef) oder auf ein anderes Topic ( topicRef). Im ersten Fall könnte z.B. vereinbart werden, dass die Abbildung einer Tomate als Identitätsnachweis ausreicht, aus der informellen Ressource tomato.gif würde also per Definition ein Published Subject Indicator werden. Die zweite Möglichkeit, die Bezugnahme auf ein Topic mit topicRef, könnte verwendet werden, um Published Subjects lokal zu ergänzen oder zu modifizieren.
::: InstanceOf
Um hierarchische Beziehungen im Sinne von Klasse-Instanz oder Superklasse-Subklasse zwischen Topics zu etablieren, wird instanceOf verwendet.

:: Associations
Associations sind neben Topics und Occurrences das dritte wichtige Element in Topic Maps. Associations modellieren die vielfältigen Beziehungen zwischen Topics.

Die Association-Modellierung für ein Tomatensuppen-Kochrezept ist im umgekehrten Sinn zugleich auch ein anschauliches Kochrezept für Topic Map Associations. Alle an der Beziehung beteiligten Topics werden in beliebiger Reihenfolge durch member-Elemente repräsentiert, und die Rolle, die sie in dieser Beziehung spielen, jeweils mit role spezifiziert: die Tomatensuppe als Mahlzeit, und Tomaten, Salz usw. als Zutaten. Die Rollen Mahlzeit und Zutaten wiederum müssten in weiterer Folge als Subklassen einer hierarchischen Superclass-Subclass-Beziehung modelliert sein: Mahlzeit als Subklasse von Nahrung, und Zutaten als Subklasse von Bestandteil (isPartOf).
Verbleibt nur mehr die Klärung der Frage, ob die Tomate als Zutat geschält sein muss oder nicht. Aber so nebensächliche Details spielen in einer abstrakten Begriffswelt keine Rolle, solange der tief implizite Wissensbegriff Gaumenfreude nicht umfassend definiert wurde.
:: Ressourcen im Topic Space
Um Wissen zu formalisieren, also durch Beziehungen und hierarchische Konzepte bis ins Detail zu erklären, muss der Kontext der lokalen Wissenslandschaft oft mit entsprechenden Informationen angereichert werden. Dazu dient das resourceData-Element. Das Kochrezept für eine Tomatensuppe könnte in diesem Fall so aussehen:

Literaturverweise
- Balzert, H.: Lehrbuch der Software-Technik, Spektrum Akademischer Verlag,
Berlin/Heidelberg, 1996
- Birbeck, M. et al.: Professional XML, 1st Edition, Wrox Press, Birmingham, 2001
- Brown, W. J. et al.: Anti Patterns, Wiley, New York, 1998
- Chen, C., Geroimenko, V.: Visualizing Information using SVG and X3D,
1. Edition, Springer, Berlin/Heidelberg, 2004
- Dueck, G.: Lean Brain Management. Erfolg und Effizienzsteigerung durch Null-Hirn,
Springer, Berlin, 2006
- Forssman, F., Willberg, H. P.: Lesetypographie, Verlag Herrmann Schmidt, Mainz, 1997
- Fuhr, N. (Editor) et al.: Advances in XML Information Retrieval:
Third International Workshop of the Initiative for the Evaluation of
XML Retrieval, INEX 2004, Dagstuhl Castle, 2004, Springer, Berlin/Heidelberg, 2005
- Gomez-Peres, A. et al.: Ontological Engineering, Springer, 2004
- Heyer, G. et al.: Text Mining. Wissensrohstoff Text, Verlag W3L, Bochum, 2006
- Jung, E. et al.: Professional Java XML, Wrox Press, Birmingham, 2001
- Kay, M.: XSLT Programmer's Reference, 2nd Edition, Wrox Press, Birmingham, 2001
- Kuhlen R. et al.: Grundlagen der praktischen Information und Dokumentation,
5. Ausgabe, K. G. Saur, München, 2004
- Krcmar, H.: Informationsmanagement, Springer, Berlin/Heidelberg, 2005
- Larman, C.: UML 2 und Patterns angewendet. Objektorientierte Softwareentwicklung,
mitp-Verlag, Bonn, 2005
- Höhn, R., Rosenkranz, H.: Standards für ontologiebasierende Anwendungen,
in Makolm, J., Wimmer, M.: Wissensmanagement in der öffentlichen Verwaltung,
Österreichische Computer Gesellschaft, Wien, 2005
- Kirk, C., Pitts-Moultis, N.: XML Black Book, Coriolis Technology Press, Scottsdale, 1999
- Markowetz, F.: Klassifikation mit Support Vector Machines. Max Plank Institut
für Molekulare Genetik, 2003
- Mizoguchi, R. (Editor) et al.: The Semantic Web ASWC 2006:
First Asian Semantic Web Conference, Beijing, China, September 3-7, 2006,
Proceedings, Springer, Berlin/ Heidelberg, 2006
- Park, J.: XML Topic Maps. Creating and Using Topic Maps for the Web,
Addison-Wesley, Boston, 2003
- Pöhm, M.: Präsentieren Sie noch oder faszinieren Sie schon?
Der Irrtum Power-Point, mvg-Verlag, Heidelberg, 2006
- Russel, S., Norvig, P.: Künstliche Intelligenz. Ein moderner Ansatz,
Prentice Hall/Deutsche Ausgabe bei Pearson Education, München, 2004
- Schneider, U.: Das Management der Ignoranz. Nichtwissen als Erfolgsfaktor,
Deutscher Universitätsverlag, Wiesbaden, 2006
- Solomon, C.: Anwendungen entwickeln mit Office, Microsoft Press, 1995
- Staab, S., Studer, R.: Handbook on Ontologies, Springer, Berlin/Heidelberg, 2004
- Stein, E.: Taschenbuch Rechnernetze und Internet, Fachbuchverlag Leibzig
im Carl Hanser Verlag, München/Wien, 2001
- W3C, World Wide Web Consortium, w3.org
|
|
|